
So, let's fast-forward through this first part. While it was revealing, it wasn’t all that great. Informative? Sure. Exciting? Nah.
So we can skip the fluff.
There I was, creating yet another C program to crack—asking an LLM (Large Language Model) to be rough with me. I told it to place whatever protections it found amusing, especially ones that might put a damper on my usual GDB shenanigans.
I whipped up a simple C program with some XOR gimmicks and handed it over to the LLM, telling it, “Go nuts. Protect this binary as if your life depends on it.”(I might be paraphrasing here).
The LLM's Attempt at a Challenge
Well, the LLM tried, but it failed pretty hard. Not because I’m some kind of binary-reversing wizard (I’m not), but because its defenses mostly relied on surface-level userspace tricks. These are the kinds of protections that look flashy but crumble under the weight of a determined debugger wielding carefully placed breakpoints.
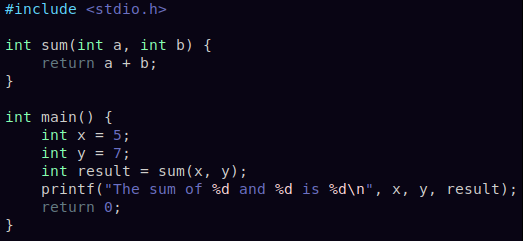
Let’s cut to the chase: here’s a snippet of the original code it generated:

Breaking the "Protections"
Most of these defenses—fake functions, misleading execution flows, or basic obfuscation (not all seen here)—can be easily defeated with a debugger. When you examine the binary at runtime, these kinds of tricks are more like a speed bump than a roadblock.
GDB was enough by itself to detect the two main weaknesses—key+encrypted password:

And voilà, a quick peek into those memory locations reveals the key and the encrypted password. Nothing we haven’t seen before:

The logic here is straightforward. By reading the ASM, we can tell there’s a xor operation happening, and the key is being repeated (via a modulo 4 operation) to match the encrypted password’s length (10 characters).
Great! From here, undoing the operation is trivial. A simple Python script does the trick:

And that’s it. We have the password, the binary is cracked, and we move on.
Lessons Learned
What’s the moral of this part? Don’t store your bloody password and key inside your binary. Ever. Seriously, it’s like leaving your house key under the mat and hoping no one checks.
This reminds me of that guy who stored his password inside his binary while working on a GitHub project with full version control. He was surprised to find others knew the pass, regardless.
What's Next?
I could create more complex C programs where the password lives elsewhere (maybe a server, maybe environment variables), but honestly, that defeats the purpose of this kind of exercise. Plus, it opens up a whole other can of worms I don’t feel like opening just yet.
Instead, we’ll dive into Binary Security: NX, ASLR, RELRO, Stack Canaries, and how these mitigations shape the reverse-engineering landscape.
It’ll be fun (or your money back—promise).




















.jpg)


