
Elves
For the past few days, I've been delving into ELF (Executable and Linkable Format) binaries—specifically focusing on their structure, behavior, and ways to manipulate them. If the subject matter is of any interest to you, then check this out.
What are ELF files?

They are a "common standard file format for executable files, object code, shared libraries, and core dumps, at least according to Wikipedia.
The magic number for ELF files is 0x7f 45 4C 46. Care to guess what's 45 4C and 46 in ASCII?
Let's look at (yet another) terribly simple C script and then look under the covers:

Not terribly impressive, but we're not trying to be terrible or to impress anyone.
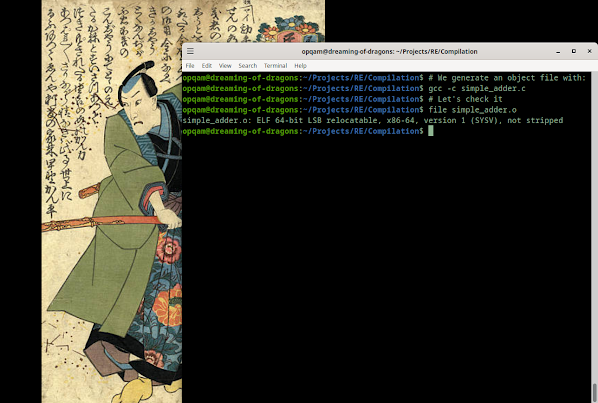
Remember when we talked a bit about the 4-step compilation process here? Instead of directly compiling this program, let's jump to the Assembly phase and look at the object file:

So, as we can see, we have a 64-bit ELF object file... relocatable. What does it mean for this to be relocatable?
It means that it's not dependent on specific memory addresses. So this file can be moved around without breaking its code. Our code isn't yet an executable. We're still short of that objective since we've not yet passed through the linking phase, which will or might add to it other object files or libraries, and then yes, produce our executable.
It means that it's not dependent on specific memory addresses. So this file can be moved around without breaking its code. Our code isn't yet an executable. We're still short of that objective since we've not yet passed through the linking phase, which will or might add to it other object files or libraries, and then yes, produce our executable.
Remember that, for the most part, programmers skip and don't even think about these steps. The compilation process takes care of all of this in the background, and only if something is untoward will the programmer be warned that one of these 4 steps went awry.
And notice as well that this file is 'not stripped'. What's this, you ask? It's informing us that the the file contains the symbol table and debugging information within it. This keeps information that is useful for debugging purposes, making it easier to analyze and understand what's happening, with tools like gdb or objdump. On the other hand, stripping our binary means that both symbol table and debugging info will be removed. The symbol table contains the names of functions, files, variables and other metadata useful for debugging or reverse engineering. And that extra debugging info shows the variable types and line numbers, for example.
So, stripping will reduce the file size, hide implementation details but also make debugging a bit harder.
Under the hood
Let's do it. It's pretty simple, actually. After finally creating our binary, we can strip it with:
strip --strip-all simple_adder
Here we can see the difference between the two files, through the use of the command readelf:

It's a bit rough around the edges, but if you look carefully, you can see two files, one stripped and one not stripped, and the difference is telling, even for such a small binary.
Obviously, stripping is also used as a countermeasure and obfuscation technique.
The readelf command that you see up there is a tool for analyzing and displaying information about ELF files. With it, we can inspect the internal structure of ELF files, such as executables, shared libraries, or object files. Yes, it's what that ELF lady is doing at the beginning of this blog post. I know. Genius.
Readelf comes in handy to debug linking issues or to understand how an executable or a library is laid out.
As per usual, man files are your friend here.
.text, .data, .bss and .rodata
Elf files have critical areas, like .text which contains executable instructions, .data which stores initialized global variables, .bss which holds uninitialized global variables and .rodata, which holds read-only data, such as constant strings.
We can inspect the .text section, which could be considered as the heart of the program (holding the executable code, really), with a tool like radare2 or objdump, for example:

As you can see, this is giving us Assembly code (in AT&T, no less... yuck) revealing function prologues, loops, and system calls.
Of course, recognizing these patterns is a vital skill for the Reverse Engineer.
Try this for yourself. Also remember to check .data and .bss with:
readelf -x .data your_file
readelf -x .bss your_file
But there's more ways to inspect your ELF files. Let's look at ldd which prints shared object dependencies and use readelf with '-r' to check relocation tables:
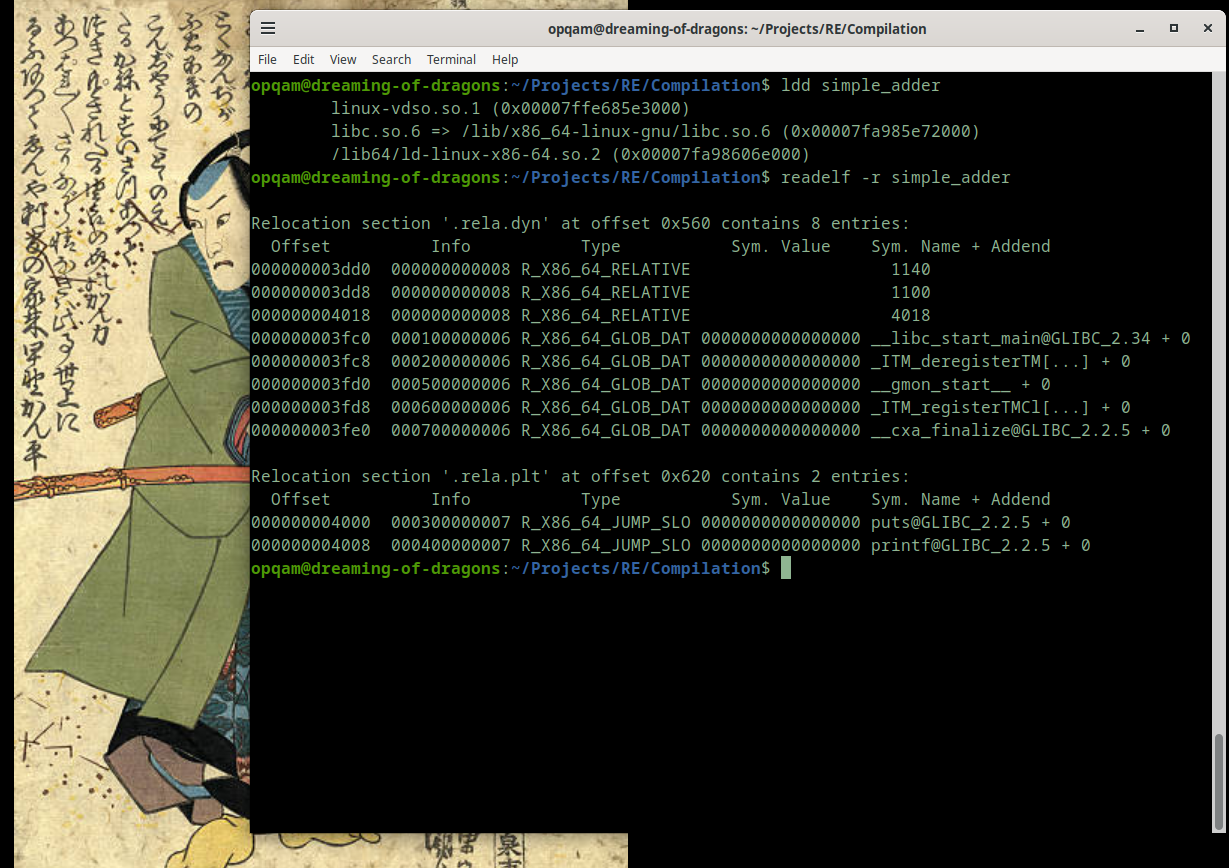
What's all of this, you say?
With ldd we can check the shared libraries within our binary. Each listed library representing a dependency. And relocation tables are essential for adjusting addresses in a dynamically loaded binary. Entries like
R_X86_64_JUMP_SLOT or R_X86_64_GLOB_DAT help resolve function calls or global variables at runtime.There's more, of course. But this stuff is much more fun to experiment with than just to talk or write about.
Go at it. Experiment with creating your own binary files and examine them with any or all of these tools (or others). Change things, check again.
No elves were harmed in the making of this blogpost. Nor any DWARF, of course.



































.jpg)


